


Why AI Probably Won't Kill Us All
Examining some of the key arguments that undermine the case for existential risk

Many, perhaps most people, dismiss fears of an impending AI apocalypse as the overly intellectualized fantasies of a bunch of nerds. To be fair, such fantasies tend to belong to the domain of religious myths and sci-fi stories, but as I explain at length in my previous article on existential risks from AI, there are plenty of good reasons to take this seriously.
In this article, I will instead make the case for why advanced AI1 is very unlikely to pose a direct existential risk to humans and why I'm personally not that worried - despite being a nerd that loves overly intellectualized sci-fi stories.

AGI = DOOM
Existential risk from AI refers to the possibility that AI could pose a threat to the continued existence of humanity or other forms of advanced life on Earth. This is a concern because AI has the potential to become vastly more intelligent than humans and could potentially act in ways that are harmful to us if it is not properly controlled or aligned with our values and goals.
In short, the core arguments for existential AI risk (sometimes called X-risk), or in other words, certain doom from advanced AI, can be summarized as follows:
All advanced AIs are super-optimizers: The core assumption is that if we build a super-optimizer or an AI that is capable of optimizing for a specific goal to an extreme degree, it will lead to an existential catastrophe for humans and possibly all or most life on earth ("doom"). This is because of "instrumental convergence," which is the idea that regardless of the ultimate goals of the AI (like "create a cure for cancer"), it will adopt certain instrumental means to achieve its goal, some or most of which will spell certain doom for humans (such as consuming all the available resources in the universe).
It's impossible to align AIs: It's impossible (or at least we won't figure out how) to make such a system "reasonable" or to perfectly align its goals with human values. This means that if we, for example, want the AI to cure cancer, it will not do what most humans would do, which is to declare victory once we are reasonably sure that we've found a cure for cancer. The AI will 1) acquire as many resources and as much power as possible to maximize its chances of finding a cure, and 2) if it finds a cure, it still can't be 100% certain that it's effective, so will continue optimizing by securing more resources and power, and so on. This is the problem of AI alignment, and we have no idea how to solve it.
Resistance is futile: There's no way to control such an advanced power-seeking system with other similar or lesser AI systems because the first AI would have a "first-mover advantage" and because any AI powerful enough to stop the first one would be as dangerous. Second, whatever counter-measures or strategies we can come up with as humans to stop or control the AI, there will always be ways for it to outsmart us because it's more or less omniscient and all-powerful.
We are default dead: Finally, the assumption is that we will invariably develop such a system by default. This could be due to 1) competitive pressures, where each company or country is trying to build the most powerful AI as quickly as possible (a sort of prisoner's dilemma), or it could be due to 2) the inherent difficulty of building an AI that's both powerful and safe. The result is that we will inevitably develop advanced AI along this path and are very unlikely to be able to do anything about it due to 1 or 2.
As a result of the above and other similar arguments, I think it’s perfectly rational to be somewhat concerned and that we put more effort into researching AI safety and alignment. Not convinced? Even if you think there's a 0.1% chance (or 0.001%, 0.00001% chance) that advanced AI would ever pose a serious threat to humans, there are a lot of other risks that pose a similar or lesser level of threat but that you wouldn't dismiss out of hand. Catastrophic asteroid impacts, all-out nuclear war, and world-ending pandemics, to name a few, could arguably have similar levels of risk, if not greater. We shan’t dismiss safety concerns out of hand - even existential ones - just because it feels farfetched.
The people that believe AI poses a grave existential risk are often called "doomers" because they see advanced AI as = near-certain doom for humanity. I'm not sure that these people would always refer to themselves as doomers, but among them are a lot of very smart people like Elon Musk, Max Tegmark, Eliezer Yudkowsky, Nick Bostrom, and Sam Harris, not to mention many prominent researchers in the AI/ML field. They express varying levels of worry, but they all believe that the possibility of "doom" is large enough to take very seriously (Eliezer believes it is all but certain.)
Bad arguments against existential AI risk
Let's start out with what I'm not arguing. There are two arguments I often hear people levy against the claim that AI poses existential risks. The first is that an AI is "just code" and will never pursue a goal that you haven't given it, a version of which even Marc Andreessen argued recently. The second is that we can unplug it if we think it becomes a threat.
Saying that AI is “just code” is about as convincing as saying that a cornered tiger who wants to eat you is just “cells and synapses.” It's trivially true but not very helpful in terms of figuring out how to survive.
Moreover, modern LLMs have reached such levels of complexity that they are, in many regards, a black box to us; we don't know exactly how they reach the conclusions that they reach. The fact that it's just code underneath doesn't make the system perfectly legible - or safe.
In terms of the second argument, unplugging or turning off an advanced AI (or multiple!) is not something we can easily assume would be possible. I wrote the following in my previous article on AI risk:
Although this is theoretically possible if we’re talking about an AI that’s running on a computer in a lab somewhere, once the AI is out in the world and has access to the Internet, or indeed if there are multiple AIs running on multiple computers or networks of computers, it’s increasingly unlikely that this strategy would work. How would you unplug the Internet?
So, if these arguments don't quite hit the mark, what are more compelling and nuanced counterpoints? Let's explore.
Better arguments against existential AI risk
I believe there are two key points one can make that undermine the X-risk hypothesis.
We won’t create true AGI: Advanced, power-seeking AGIs with strong strategic awareness and reasoning may pose existential risks that are more or less impossible to fully pre-empt and counter-act. But it's either impossible to create such AGIs or such a distant possibility that we can’t do anything about it anyway.
If we create AGI it will not be power-seeking: Even though power-seeking and super-optimizing advanced AIs could pose an existential threat in theory, we shouldn't assume that the kind of AGI we will create will be power-seeking in the way that humans are power-seeking.
Let's unpack these in more depth.
1. We probably won’t create true AGI in the first place
First, we need to define what AGI is and isn't so as to avoid creating a strawman. In the previous article, I defined AGI as follows:
AGI (Artificial General Intelligence) refers to AI systems that can perform many intellectual tasks that are at least as difficult as those that a typical human can perform. AGI systems are capable of learning and adapting to new tasks and situations and can potentially perform any task that a human can perform.
In addition, a true AGI needs to have a model of the world that enables it to have the sort of strategic awareness and the wherewithal to understand the relationship between “itself” and objects in the world so as to be able to navigate in it. It needs to have causal reasoning to understand "how things work" in the real world and the ability to pursue long-term goals coherently across domains.
It is not unreasonable to assume that an AGI that has these properties would, by default, lead to human extinction - for the reasons outlined in the introduction (instrumental convergence and so on). After all, such an AGI would, by all accounts, be near-omniscient and omnipotent. It would have a complete model of the world, reasoning capabilities, and the ability to pursue goals across different domains that enable it to pose an existential threat (i.e., by being able to figure out a plan, pre-empt human attempts to stop it, and carry out that plan in the real world; perhaps a plan that involves, manipulation, bioweapons or other dangerous tech.)
But the question remains if we will ever be able to create true AGI in the first place and whether the current AI paradigm is developing in that direction. Although expert opinions diverge, there are good reasons to be skeptical that the current machine-learning paradigm will produce that sort of AGI any time soon.
We're not on the path to AGI
For one, AI systems like the LLMs that power ChatGPT have yet to develop a coherent world model and don't seem to have an internal understanding of the output they generate. While they can create very impressive-sounding output and certainly express a façade of reasoning, the results rely on a statistical, brute-force method and not on “true” understanding.
As Sarah Constantin argues at length, AIs (like LLMs) don't pose a threat unless they develop a coherent a world model (and sufficient strategic awareness):
For an AI to persistently pursue a goal in the world that could kill us all, it’s going to need substantial generalization and prediction abilities. [...] Any physical means of producing human extinction is necessarily a totally unprecedented state of the world, which the AI won’t have observed before, and which won’t be in its training data.
Current models also don't have the ability to reason causally, as they are statistical prediction models. And an intelligent and autonomous agent needs to be able to reason causally (to "understand") in order to achieve complex goals:
Agency requires reasoning about the consequences of one’s actions. “I need to do such-and-such, to get to my goal.” This requires counterfactual, causal reasoning. [...] Mere statistical prediction (“what is the distribution of likely outcomes, conditional on my having taken a given action”) is not the same thing.
The famous psychologist Steven Pinker has echoed similar doubts with regard to the viability of AGI. Yet he goes even further:
Understanding does not obey Moore’s Law: knowledge is acquired by formulating explanations and testing them against reality, not by running an algorithm faster and faster. Devouring the information on the Internet will not confer omniscience either: big data is still finite data, and the universe of knowledge is infinite.
LLMs like ChatGPT don’t really understand what it is they are saying or doing. They can explain things coherently because the model is predicting what makes the most sense to say based on its training. For example, we can get such an AI to output that 2+2 = 4 and even explain why this is the case, but it does not do this because it understands the principles of arithmetic but because this is the most likely output that satisfies its reward function. An LLM can tell us that it is an LLM, but that doesn’t mean it has a concept of itself as an entity in the world.
Finally, an AGI also needs to be able to pursue its goals across different domains, what Constantin refers to as "Goal Robustness Across Ontologies." This means that in order to achieve a complex and multi-faceted goal, one needs to understand the various steps of achieving that goal and to be able to pursue it consistently, even though various parts of the plan change in unexpected ways.
For an AI to be able to solve real-world problems, it needs to be able to encounter unanticipated problems and expand its model, its ontology of possibilities, to accommodate them, and it needs to *translate* its old goal into the new ontology in a “natural” way.
It could be the case that LLMs eventually develop an advanced world model and strategic awareness as a by-product of all the training and knowledge they have. Perhaps the neural nets they are based on and the vast amount of training data lead to correlations so strong that they learn predictable and foundational rules about the world as a by-product. And having learned such foundational rules (first principles), an LLM would then be able to give much better answers and take more coherent actions as an agent. Eventually, something like a true AGI starts to emerge from the soup of training data and RLHF.
Although this doesn’t strike me as completely implausible, I don’t see why it would be the default path of evolution for such systems.
Moreover, most AI researchers and companies today aren't working on the kind of AI models that are most likely to lead to the AGI described above, the kind that doomers are worried about. So more advanced LLMs with more and more compute power will be able to produce very capable AI agents of the sorts we have today, potentially with really profound effects on the world economy, but aren't likely to evolve into AGIs.
All in all, this undermines the expectation that we are going to see that kind of AGI in just a few years from now and that the singularity will happen shortly thereafter.
Questioning the concept of intelligence
The underlying assumption behind the claim that AGI poses existential risks (and indeed that AGI also has transformative benefits) is that advanced intelligence is the fundamental capability that underlies all other abilities - an argument that I've made myself:
Advanced AIs are unlike other technologies like nuclear weapons because intelligence is more fundamental than specific technologies. All inventions and technologies are the results of intelligence + applied knowledge. To get nuclear weapons, you first need (enough) intelligence. In a sense, anything that we would want to do or that can be discovered about the universe is just a matter of having the right knowledge.
But this is not necessarily the only view of what intelligence is. Steven Pinker argues extensively against X-risk, in part because he claims that intelligence is by its very nature more narrow:
There’s a recurring fallacy in AI-existential-threat speculations to treat intelligence as a kind of magical pixie dust, a miracle elixir that, if a system only had enough of it, would grant it omniscience and omnipotence and the ability to instantly accomplish any outcome we can imagine. This is in contrast to what intelligence really is: a gadget that can compute particular outputs that are useful in particular worlds.
In a conversation with Scott Aaronson, Steven Pinker also argues that the idea of superintelligence itself is pure fantasy:
If you’ll forgive me one more analogy, I think “superintelligence” is like “superpower.” Anyone can define “superpower” as “flight, superhuman strength, X-ray vision, heat vision, cold breath, super-speed, enhance hearing, and nigh-invulnerability.” Anyone could imagine it, and recognize it when he or she sees it. But that does not mean that there exists a highly advanced physiology called “superpower” that is possessed by refugees from Krypton! It does not mean that anabolic steroids, because they increase speed and strength, can be “scaled” to yield superpowers. And a skeptic who makes these points is not quibbling over the meaning of the word superpower, nor would he or she balk at applying the word upon meeting a real-life Superman. Their point is that we almost certainly will never, in fact, meet a real-life Superman. That’s because he’s defined by human imagination, not by an understanding of how things work. We will, of course, encounter machines that are faster than humans, and that see X-rays, that fly, and so on, each exploiting the relevant technology, but “superpower” would be an utterly useless way of understanding them.
The concept of AGI comes from the idea that, as humans are a form of general intelligence, AGIs will be able to do everything that humans can do, only much better and faster, with the scalability that comes from being computers. This idea is what has produced most accounts of AI in science fiction. But what if there is no truly "general" kind of intelligence at all? Instead, every kind of intelligence is actually narrow and adapted to its particular domain. Even humans' intelligence. It’s not obvious why artificial intelligence will be different.
2 AGI is not going to be (too) power-seeking
In my previous article on this topic, I wrote about why AGIs would have power-seeking behaviors:
They would be power-seeking, not necessarily in an evil mustache-twirling kind of way, but more so in an instrumental end-justifies-means kind of way because it’s easier to achieve your goals in the world (whether they are benevolent or evil) if you have more power. For instance, a politician may resort to dishonesty or accept questionable donations to secure a win in the upcoming election, not out of malice, but because they understand that they require political leverage to enact the positive changes they want for the world.
The computer scientist Stuart Russel made this point by saying that "You can't fetch the coffee if you're dead," in reference to the fact that you can't accomplish anything unless you first make sure that you are alive and have the resources or energy to do so. And there are both theoretical arguments and experimental research that show AIs will, at least in some adversarial contexts, learn to manipulate and take resources from others as a sort of pre-emptive strategy (which is seen as evidence for power-seeking behavior.)
Yet, in the real world, such behavior is far from guaranteed to evolve in AIs, at least not to the extreme degree that doomers claim. Power-seeking is useful in the sense that you need some degree of power to achieve your goals, and more power is always better. But absolute power isn't always necessary to achieve "regular" goals like fetching coffee to a satisfying degree, at least not unless you're in a zero-sum, adversarial environment. Why assume this to be the case?
Arguments in favor of AI = doom assume AIs are incentivized to achieve their goals at any cost (super-optimization) and that they will be abe able to acquire all the resources they need (such as by consuming the power of stars) because they are superintelligent. But in practice, both humans and AIs are subject to resource and time constraints. Jason Crawford makes the point that super-optimization toward a specific goal is very costly and that humans have no economic incentives to build systems that would operate like that:
More to the point, there is no economic incentive for humans to build such systems. In fact, given the opportunity cost of building fortresses or using the mass-energy of one more star (!), this plan would have spectacularly bad ROI. The AI systems that humans will have economic incentives to build are those that understand concepts such as ROI. (Even the canonical paperclip factory would, in any realistic scenario, be seeking to make a profit off of paperclips, and would not want to flood the market with them.)
In other words, it's far from certain that such power-seeking and super-optimizing behaviors are bound to emerge in sufficiently advanced systems. This means that even if we create AGI(s) with all the agency and strategic abilities we would want them to have, the default expectation should be that it will be no more power-seeking than what is needed - which may be very much but not infinitely much.
AI alignment might not be such a big problem
Another related but less central point is that about (mis)alignment. Doomers fear that when (or if) we get AGI, we will not have figured out how to align them with us so as to avoid an existential catastrophe. (Presumably, because we have thought about it for a long time and don’t know how to do it yet.)
An example of misalignment I’ve seen mentioned frequently is that of a robot simulation that managed to trick its human evaluators:
Relatedly, in some domains our system can result in agents adopting policies that trick the evaluators. For example, a robot which was supposed to grasp items instead positioned its manipulator in between the camera and the object so that it only appeared to be grasping it [...].
Doomers take this and similar examples to mean that this sort of misalignment with human goals is just the beginning and that when we have AIs capable of unprecedented levels of manipulation, they will kill us all unless we have aligned them enough with us (so as to value human life). But what seems more likely is that we will continue to see misalignment of that more mundane kind (albeit at a larger scale). Meaning that AIs will manipulate humans and game the system in a lot of ways that aren’t very different from what we’re used to dealing with already.
In any case, I’ll echo Scott Alexander in that it’s more likely we will create somewhat aligned AIs that can be deployed to stop other more dangerous unaligned AIs before they kill us all, rather than the reverse because the latter will be operating under “maximally hostile conditions”:
So the optimists’ question is: will a world-killing AI smart and malevolent enough to use and deploy superweapons on its own (under maximally hostile conditions) come before or after pseudo-aligned AIs smart enough to figure out how to prevent it (under ideal conditions)?* Framed this way, I think the answer is “after.”
Lastly, much of the AI safety discussion among doomers (especially within the rationalist, EA, and AI research communities) has typically centered around how we can prevent an unaligned AGI from being created or deployed into the wild. That is, how to ensure the safety of the AI system ex-ante - given the assumption that once it has been created, there's no way to stop it from destroying the world should it want or need to. Instead, I’m partial to the approach suggested by Jose Luis Ricon of the blog Nintil, which is to focus on improving the resiliency and robustness of our systems and institutions. Rather than just trying to prevent an AI-related catastrophe, assume it can happen and work to make us safer regardless:
Progress will be made better understanding and engineering intrinsically safer AIs, but I am as optimistic or more about work on societal resilience to AGIs than I am about making systems that most surely do no harm; as hard as it may seem, it seems easier and more practical to me to work on governance, improving cybersecurity, etc, than to work on making AI systems safe. This view is probably unusual: It seems there are two big camps; one is doom-by-default, alignment is hard, and the other is doom-can-be-averted, alignment is easier. A third camp is doom can be averted, alignment is somewhere in between in difficulty, but societal resilience to AGI can be increased.
Is doomerism a secular religion?
Every human religion or culture has mythologies with stories of superhuman abilities, omnipotence, salvation, and apocalypse. It’s hard not to notice a similar tendency undergirding the reasoning of doomers.
When you're arguing that humans will one day create an ASI that is omniscient and all-powerful and that the apocalypse is coming, you come off sounding a bit like a religious nut. I'm not saying that doomers are just like religious zealots, but there's something deeply human in creating or imagining deities.
Technological optimists on the other side of the spectrum, also sound a lot like this. These are the people that believe in the AI Singularity, most prominently fronted by Ray Kurzweil. The singularity is the event where AI reaches superintelligence. And once we've reached the singularity, all bets are off.
The optimists imagine a utopian future, while the pessimists believe it will bring about the apocalypse.
Of course, just because someone makes arguments with a religious flair doesn't make them a kook, nor does it mean they are wrong. But it does make you squint your eyes and perk your ears a bit; haven't we heard all of this before?
Deducing our way to doom
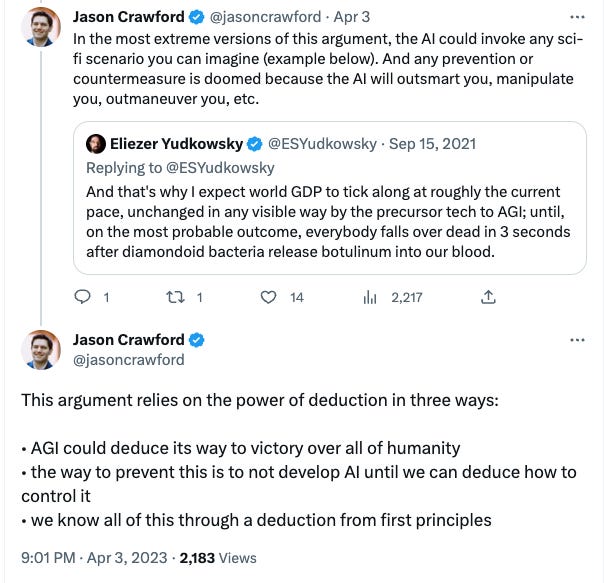
Moreover, most of the AI = Doom arguments have been constructed from a very philosophical style of reasoning, namely deduction. Benedict Evans put it quite aptly on Twitter:

Jason Crawford made a similar point in a Twitter thread about how to approach AI safety, pointing out that the X-risk arguments rely heavily on deduction from first principles. But the problem is that the first principles are unknown at this stage, so even a logically coherent argument may be pure speculation.
Steven Pinker also made the same point, but in a slightly more derisive manner:
They start with a couple of assumptions, and lay out a chain of abstract reasoning, throwing in one dubious assumption after another, till they end up way beyond the land of experience or plausibility. The whole deduction exponentiates our ignorance with each link in the chain of hypotheticals, and depends on blowing off the countless messy and unanticipatable nuisances of the human and physical world.
Seen like this, AGI sounds a lot like the rationalist God in Aristotelian clothing.
There are a lot of things one can worry about; why worry about AI?
It's very hard to predict the future. It's not as hard to create a plausible-sounding account of how AI can evolve and grow more powerful. And given some also-reasonable assumptions about intelligence, power, and instrumental goals, you have everything you need to paint a concrete picture of existential doom á la AI.
I noted earlier that it makes sense to be a least a little worried about X-risk from AGI, even if you believe the probability is very low. But this also goes the other way. If you are the kind of person that is having nervous breakdowns because you believe that AGI will spell certain doom, you're probably giving this particular risk undue weight compared to many other potentially existential threats that are also very unlikely to materialize. The point is that all these outcomes are very distant; why worry about X-risk from AI much more than others? Tyler Cowen made a similar point:
Existential risk from AI is indeed a distant possibility, just like every other future you might be trying to imagine. All the possibilities are distant; I cannot stress that enough. The mere fact that AGI risk can be put on a par with those other, also distant possibilities, simply should not impress you very much.
This could sound like a case of whataboutism. My point is not to dismiss worries about X-risk as unfounded. After all, just because we have no prior experience with something or no hard data at hand to predict how likely something is, it doesn't mean we can dismiss it as a risk. Rather, it is to point out that you should calibrate your worries.
The mood affiliation fallacy states that you will match any specific ideology or view to your given psychological mood. For example, if you are a pessimistic person discussing climate change, you tend to favor evidence in support of a pessimistic conclusion.
Applied to the X-risk debate, perhaps doomers just have a more pessimistic or paranoid underlying psychology or mood? And find the arguments in favor of existential and apocalyptic outcomes much more compelling.
Of course, the same can be said about overly optimistic people.
Scott Aaronson said that:
…if you ask, “why aren’t I more terrified about AI?”—well, that’s an emotional question, and this is my emotional answer.
I think it’s entirely plausible that, even as AI transforms civilization, it will do so in the form of tools and services that can no more plot to annihilate us than can Windows 11 or the Google search bar. In that scenario, the young field of AI safety will still be extremely important, but it will be broadly continuous with aviation safety and nuclear safety and cybersecurity and so on, rather than being a desperate losing war against an incipient godlike alien. If, on the other hand, this is to be a desperate losing war against an alien … well then, I don’t yet know whether I’m on the humans’ side or the alien’s, or both, or neither! I’d at least like to hear the alien’s side of the story.
Maybe it’s because of my mood, but I’m partial to this sentiment. After all, if AI does kill us in the end, it would be a hell of a way to go.
Is AGI inherently unsafe?
As every technology has some level of risk associated with it, it can be instructive to clearly define the type of risks it poses and where to put the bar for safety. In this manner, Jason Crawford outlined a framework for how to think about the relative safety of technologies along 4 levels:
So dangerous that no one can use it safely (weaponized smallpox virus?)
Safe only if used very carefully (nuclear weapons?)
Safe unless used recklessly or maliciously (nuclear energy?)
So safe that no one can cause serious harm with it (a watch?)
If you believe that the risk from advanced AI is both existential and very high, then you’re saying that it’s a level 1 technology because there’s no way we can use this technology in a safe manner as any way it’s used is bound to bring the end of humanity or human civilization as we know it. And therefore, all development must be stopped or paused until we can figure out how to do it safely.
My sense is that advanced (and contemporary) AI is unlikely to categorically be level 1, and is most likely level 3, perhaps level 2 for certain applications. A reason for this is that one of the more likely risk scenarios comes from cybersecurity-related threats like hacking, malware, and even social engineering - whether deployed by humans first or initiated by the AI itself. This is squarely a level 3 kind of risk.
Of course, a sufficiently advanced AI might try to hack government or corporate systems to obtain secret or dangerous info or tech, to disrupt the economy, and/or to create bioweapons, and so on. But hacking and cybersecurity threats are already major problems in society even without AI, and we’ve been pretty successful in dealing with those. I don’t doubt that it could get worse before it gets better, but overall, AI will also play a big role when it comes to mitigating new (and old) cybersecurity-related threat vectors from malicious agents, whether artificial or organic.
So if AGI is more like level 2 or 3 tech, then doomers overestimate the risks and underestimate the ability of humans to control and manage it. After all, humans have a pretty decent track record of managing complex and risky technologies such as nukes and biotechnology without causing major catastrophes (so far, at least). And we have and can develop effective international governance mechanisms to ensure that potentially harmful tech is largely used for beneficial purposes; we did so even in adversarial conditions like during the Cold War. Why would it not be possible with AI?
Given AI has this level of risk (safe if used responsibly and with caution), then the way to deal with such risks is to continuously test and validate new AI systems as they are developed, which is largely what we are doing from what I can tell. It is when the technology is real (and deployed, at least in a testing environment) that we are best able to figure out what the problems are and how we can solve them. Trying to imagine all the different possible dangerous scenarios beforehand is probably not enough anyway.
Stopping or slowing down AI development may be the biggest risk
I agree with the doomers that AI is "not just a technology"; it is a technology that can think as intelligence is fundamental to every other technology. But for all the reasons mentioned above, I find it implausible that the kind of advanced AI that we are likely to develop would be so broadly capable and (super)intelligent that it will pose a direct existential threat and that we will be incapable of managing it2.
While doomers fear the power of artificial intelligence will spell the end of humanity, it’s because of the power of intelligence that I’m mostly optimistic about what we will be able to do - what we have to do - with AI in order to solve all our biggest problems and continue improving the world (and the universe!).
Nevertheless, I agree with those that worry about AI and believe we should put more effort into AI safety and AI alignment, yet some doomers argue that a small but existential risk is worth extreme preventative measures. By definition, a very small risk is unlikely, and there are real opportunity costs to just trying to limit the downside. A point that Robin Hanson made:
Worriers often invoke a Pascal’s wager sort of calculus, wherein any tiny risk of this nightmare scenario could justify large cuts in AI progress. But that seems to assume that it is relatively easy to assure the same total future progress, just spread out over a longer time period. I instead fear that overall economic growth and technical progress is more fragile that this. Consider how regulations inspired by nuclear power nightmare scenarios have for seventy years prevented most of its potential from being realized. I have also seen progress on many other promising techs mostly stopped, not merely slowed, via regulation inspired by vague fears. In fact, progress seems to me to be slowing down worldwide due to excess fear-induced regulation.
I share his and others’ concerns that we could be headed down a path where we may over-regulate this technology. Excess regulation can stifle the innovation around new AI paradigms, startups, and tech that would have enabled all the world-changing benefits we do want. My fear is that the same thing could happen with AI; we could be killing it in its cradle.
It should go without saying, though, that there are plenty of other risks associated with AI that are worth addressing and that just because AI won't kill us all, it can still lead to some pretty bad stuff. I don't imagine anything else. But my sense is that AI is likely to be very good for us, despite all of the risks. Here, I’m on the same side as Marc Andreessen.
You can take “advanced AI” and other similar terms I use as referring to systems with AGI-level capabilities and beyond.
In true Bayesian spirit, some people try to put a number on the likelihood of AI leading to an existential catastrophe, which is a good exercise because it forces you to be specific with what you mean when you say that something is "unlikely" or "very unlikely." This probability is often referred to as p(doom). Eliezer Yudkowski thinks that it is greater than 90% or p(0.9). Scott Alexander thinks p(0.33). Scott Aaronson, quoted above, said he thinks it’s around 2% or p(0.02). I'll assume someone like Steven Pinker believes it is far, far less than 0.0000001%.
A few years ago, I would have probably dismissed AI = Doom as impossible. Now I still find it a remote possibility, but far too likely to say that it's almost impossible. So if I have to put a number on it, my p(doom) would be something like p(0.001) or 0.1%. Here I’m referring to the chance/risk that we will develop power-seeking super-optimizing AGI based on the current AI paradigm. Which, based on the conclusions above, I don’t think is very likely. If, on the other hand, the tech takes a different development path and we are likely to create that kind of AGI, I’ll have to update my priors, as it were.
What about now in 2024? Have you changed your views whatsoever?